Maintaining Network Performance as Data Centers Scale to 100G and 400G
The transition from 10G and 40G infrastructure to 100G and 400G data center networks is no longer aspirational. It is operational reality. Driven by cloud-native workloads, AI/ML clusters, east-west traffic growth, and storage replication demands, high-speed architectures are becoming the baseline.
However, scaling bandwidth does not automatically guarantee performance.
As link speeds increase, visibility gaps widen, packet loss becomes more expensive, and troubleshooting becomes more complex. Maintaining performance at 100G and 400G requires not just faster switching, but a deliberate visibility and monitoring architecture designed for high-throughput environments.
Bandwidth Pressure
Higher-speed fabrics reduce tolerance for packet drops, oversubscription, and delayed analysis.
Blind Spots Scale Too
Without deterministic access, monitoring fidelity drops precisely when traffic complexity is highest.
MTTR Gets Compressed
At 100G and 400G, troubleshooting windows are shorter and the cost of being wrong rises fast.
The Hidden Challenge of High-Speed Scaling
Upgrading to 100G or 400G dramatically increases throughput, but it also compresses troubleshooting timelines and amplifies failure impact.
At 400G:
- A microburst can drop millions of packets in milliseconds
- A single misconfigured link can impact thousands of sessions
- Tool oversubscription becomes catastrophic
- Packet capture at line rate becomes technically demanding
Traditional SPAN-based monitoring architectures frequently fail at these speeds. Packet drops, blind spots, and overloaded monitoring tools become common failure points.
Performance assurance at 100G and 400G requires three foundational capabilities:
Lossless Traffic Access
Deterministic acquisition from the network so analytics begins with complete, reliable inputs.
Intelligent Distribution
Filtering, load balancing, and tool protection to keep monitoring infrastructure sustainable.
Retention and Analytics
High-performance ingestion and historical analysis that hold up under extreme data rates.
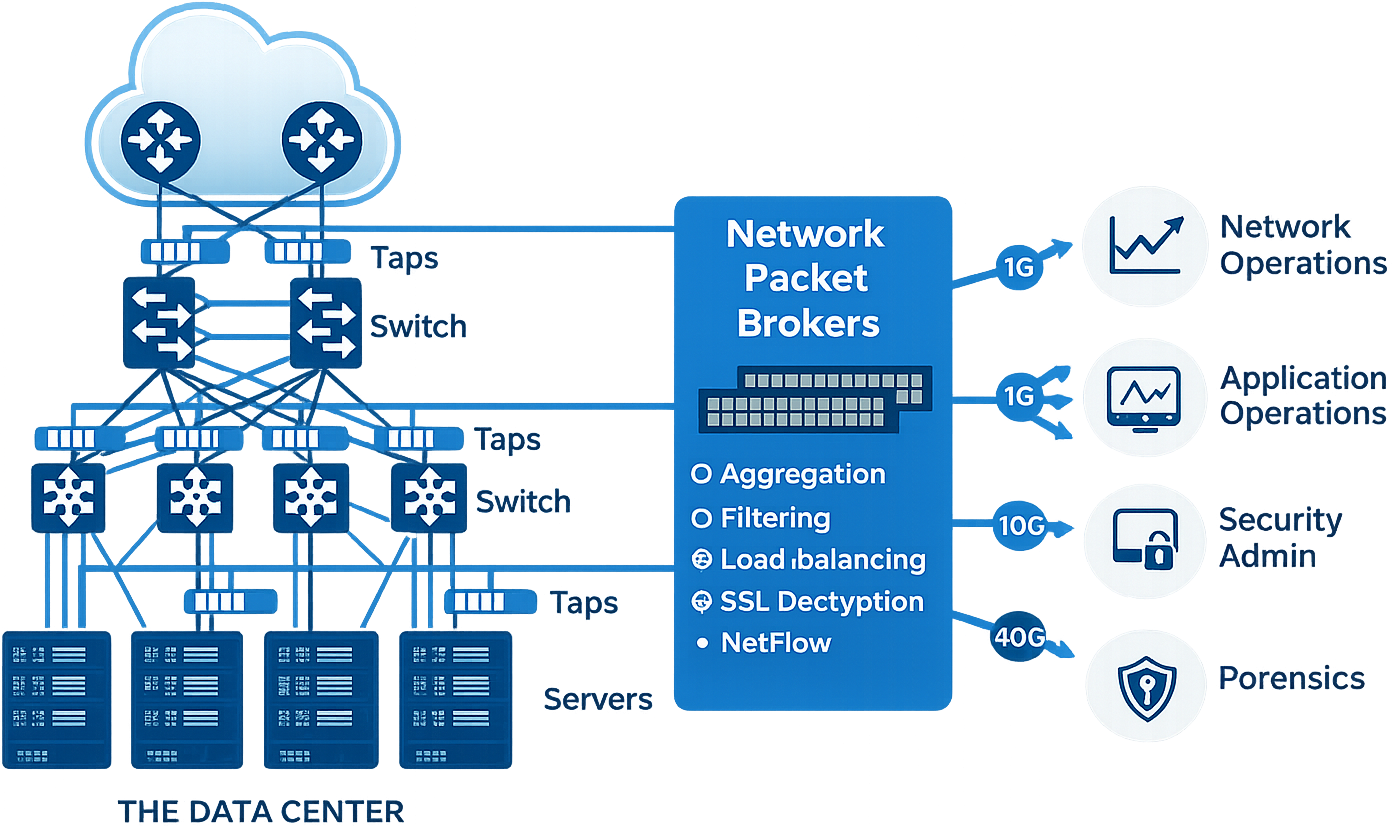
Eliminating Blind Spots with Purpose-Built Traffic Access
High-speed environments demand deterministic traffic access.
Using production switches for mirroring often results in:
What Goes Wrong with Ad-Hoc Monitoring
- Oversubscribed SPAN ports
- Inconsistent packet replication
- Monitoring-induced performance degradation
What a Packet Broker Layer Fixes
- Lossless traffic aggregation at 100G/400G
- Line-rate filtering and load balancing
- Tool protection against oversubscription
- ERSPAN and advanced encapsulation support
- Intelligent deduplication before analytics
A dedicated packet broker layer, such as PacketMaestro and PacketMaestro-Pro, guarantees that monitoring tools receive only relevant traffic at sustainable rates without compromising production performance.
Why Monitoring Tools Fail at 400G
Many legacy monitoring systems were designed for 1G to 10G environments. At 100G and above:
- Storage backends cannot ingest data fast enough
- Indexing engines become bottlenecks
- Query performance degrades under high-cardinality telemetry
- Long-term retention becomes cost-prohibitive
High-speed networks generate massive volumes of flow records, metadata, and packet data. Without optimized ingestion pipelines and compression strategies, analytics platforms become the weak link.
This is where a scalable data platform like FMADIO becomes critical.
Turning High-Speed Traffic into Actionable Insight
At 100G and 400G, it is not about capturing everything. It is about capturing intelligently.
A high-performance data retention and analytics platform such as FMADIO provides:
- High-throughput ingestion architecture
- Efficient compression optimized for time-series and packet-derived data
- Tiered storage for balancing cost and performance
- Sub-second query capability on large historical datasets
- Automated detection of data gaps and ingestion anomalies
When integrated with intelligent traffic distribution from PacketMaestro, FMADIO ensures that:
Maintaining Performance Under Load
As data centers scale, east-west traffic patterns become more complex. AI clusters, storage fabrics, and containerized workloads generate unpredictable microbursts and high-entropy traffic patterns.
Maintaining performance requires:
- Deterministic traffic access architecture
- Horizontal scalability of monitoring infrastructure
- Graceful degradation under load
- Automated self-healing and fault isolation
- Real-time visibility into ingestion health and packet integrity
A properly engineered visibility layer ensures that when performance anomalies occur, operators have the data required to diagnose root cause, not just symptoms.
The Operational Risk of Faster but Blind
Many organizations focus their budget on faster switches and optics but neglect monitoring architecture. The result is a paradox: the network is faster, but observability is weaker.
At 400G, troubleshooting without full-fidelity visibility is operationally risky. Packet drops at the monitoring layer can lead to:
- Missed security events
- Incorrect performance baselines
- Misleading KPIs
- Extended Mean Time to Resolution (MTTR)
High-speed infrastructure demands equally high-performance visibility.
A Modern Architecture for 100G and 400G Environments
To maintain performance as data centers scale, organizations should adopt a three-tier approach:
This layered architecture prevents oversubscription, reduces monitoring-induced packet loss, and ensures scalable analytics as throughput grows.
Final Thoughts
Scaling to 100G and 400G is inevitable. Scaling visibility is optional, but essential.
Organizations that treat monitoring as an afterthought will struggle with blind spots, inaccurate KPIs, and extended outages. Those that architect for high-speed visibility from the outset will gain:
- Faster troubleshooting
- More accurate performance baselines
- Reduced operational risk
- Stronger security posture
- Lower long-term monitoring costs
At 400G, performance is not just about bandwidth. It is about control, accuracy, and complete visibility.
Engineer Visibility for High-Speed Growth
Design a 100G and 400G monitoring architecture that protects tools, preserves packet fidelity, and scales with your data center.